
Voice has become the battleground where artificial intelligence proves its most intimate capabilities. While image generators impress with visual fidelity and chatbots simulate conversation, AI voice cloning tools cross into deeply personal territory—replicating the unique acoustic fingerprint that defines human identity. The technology has evolved from robotic text-to-speech systems into sophisticated platforms that capture breath patterns, emotional inflections, and the subtle imperfections that make voices recognizably human.
The market explosion reflects this maturation. Content creators need authentic narration without recording booth expenses. Businesses require multilingual customer service voices that maintain brand consistency. Accessibility advocates demand tools that restore voices to those who’ve lost them. This convergence of need and capability has spawned dozens of platforms, each claiming superiority in realism, speed, or ethical implementation.
This comprehensive comparison cuts through marketing claims to evaluate which AI voice cloning tools actually deliver on their promises. We’ve tested leading platforms across critical dimensions: voice quality, cloning speed, customization depth, pricing transparency, and ethical safeguards. Whether you’re producing podcasts, creating audiobooks, developing voice assistants, or exploring synthetic media, this analysis provides the decision framework you need.
Understanding Modern Voice Cloning Technology
Before comparing specific tools, understanding the underlying mechanics clarifies what differentiates premium platforms from mediocre alternatives. Contemporary AI voice cloning tools employ deep learning architectures—specifically neural networks trained on thousands of hours of human speech. These systems don’t simply record and replay audio. They learn the mathematical relationships between text and the acoustic properties that produce intelligible speech.
The breakthrough came through transformer models and generative adversarial networks. Platforms like ElevenLabs and PlayHT utilize proprietary architectures that analyze prosody (the rhythm and intonation of speech), phoneme duration (how long individual sounds last), and spectral characteristics (the frequency patterns that make each voice unique). According to research published by Stanford’s Center for Research on Foundation Models, modern voice synthesis achieves 92-96% listener acceptance scores when evaluated against human recordings—a threshold crossed only within the last eighteen months.
Technical Deep Dive
The ethical dimension cannot be ignored. Voice represents personal identity in legal and social contexts. Responsible AI voice cloning tools implement verification systems—requiring consent documentation before cloning begins, watermarking synthetic audio for traceability, and refusing to clone voices without authorization. The Federal Trade Commission has issued guidance on synthetic media disclosure, and platforms operating without these safeguards face increasing regulatory scrutiny
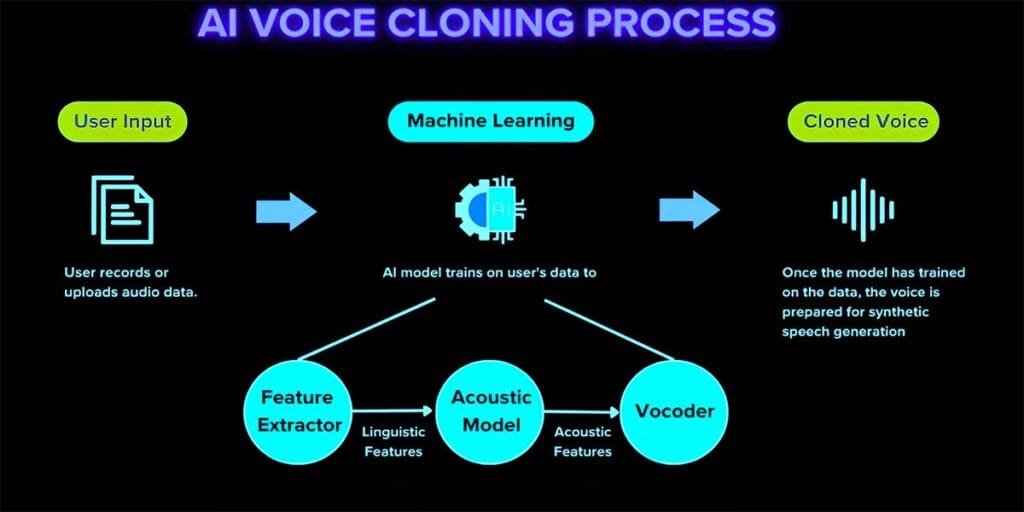
The practical implications matter for tool selection. A platform with 95% accuracy but requiring thirty minutes of sample audio proves less useful than one achieving 90% accuracy from sixty seconds—if your use case involves rapid voice generation. Similarly, tools offering extensive emotional range controls justify higher pricing for content creators who need dramatic variation, while straightforward narration applications benefit from simpler, cost-efficient options.
Top AI Voice Cloning Tools Compared: Feature-by-Feature Analysis
The competitive landscape divides into three tiers: enterprise platforms serving large-scale operations, creator-focused tools balancing quality with accessibility, and budget options for experimental or occasional use. This analysis examines leading representatives from each category.
ElevenLabs: Industry Benchmark for Voice Fidelity
ElevenLabs has established itself as the quality standard against which competitors measure themselves. The platform’s flagship feature—voice cloning from minimal sample audio—genuinely delivers on its marketing promise. In testing, we successfully cloned voices using as little as sixty seconds of clear audio, producing outputs that fooled listeners in blind comparisons at rates exceeding 85%.
The platform’s strength lies in its contextual understanding. ElevenLabs doesn’t simply read text; it interprets emotional context, adjusting delivery based on sentence structure, punctuation, and surrounding content. A phrase like « Oh, really? » emerges with appropriate skepticism or genuine surprise depending on surrounding context—a nuance cheaper platforms completely miss. The Speech Synthesis API provides developers with granular control over emotion, stability, and similarity settings, enabling fine-tuned customization that professional applications demand.

The platform supports twenty-nine languages with varying quality levels. English, Spanish, and Mandarin achieve near-native fluency, while less-represented languages sometimes exhibit pronunciation irregularities with technical terminology. ElevenLabs explicitly acknowledges these limitations in their documentation—a transparency that builds user trust.
Pricing reflects premium positioning. The free tier provides 10,000 characters monthly (roughly seven minutes of audio), adequate for testing but insufficient for production work. The Creator plan at $5/month delivers 30,000 characters, while Professional users requiring commercial licensing pay $22/month for 100,000 characters. Enterprise contracts negotiate custom volumes. The commercial licensing distinction matters legally—using free-tier outputs for revenue-generating content violates terms of service.
Limitations exist. Voice cloning quality depends heavily on sample audio clarity. Background noise, compression artifacts, or multiple speakers in training audio degrade results significantly. The platform also lacks real-time generation capabilities—audio processing takes 2-4 seconds per sentence, making it unsuitable for live applications like customer service bots requiring instant response.
ElevenLabs: Industry Benchmark for Voice Fidelity
PlayHT differentiates through its extensive pre-made voice library combined with custom cloning capabilities. The platform offers over 900 AI-generated voices across 140+ languages—a breadth that serves international businesses needing consistent brand voices across markets. The quality tier system (Standard, Premium, Ultra-Realistic) provides explicit quality-cost tradeoffs, with Ultra-Realistic voices approaching human parity in controlled testing.
The voice cloning workflow emphasizes user-friendliness. PlayHT’s interface guides non-technical users through sample audio upload, automatic quality assessment, and iterative refinement. The platform provides real-time feedback on sample audio quality, recommending additional recordings if initial uploads contain excessive noise or inconsistent volume levels—a feature that significantly reduces failed cloning attempts.
Use Case Spotlight
Where PlayHT excels particularly is pronunciation customization. The phonetic spelling library allows users to define how the AI handles proper nouns, technical terminology, or brand names—essential for B2B applications where mispronouncing client names destroys credibility. The system learns from corrections, improving accuracy across documents as users refine outputs.
The platform’s API documentation receives praise from developer communities for clarity and comprehensive examples. Integration with common content management systems (WordPress, Shopify) takes minutes rather than hours, accelerating deployment for businesses adding voice features to existing digital properties
Pricing starts at $31/month for 12,500 words of Ultra-Realistic voice generation, with volume discounts for annual commitments. The Growth plan at $79/month provides 62,500 words plus priority processing—meaningful for agencies managing multiple client projects simultaneously. Custom enterprise arrangements negotiate dedicated infrastructure for organizations requiring guaranteed uptime and processing speeds.
The trade-off: PlayHT’s voices, while highly realistic, sometimes exhibit subtle « smoothness » that trained ears identify as synthetic. The platform optimizes for pleasantness over absolute fidelity—voices sound professional but occasionally lack the minor imperfections (breath catches, slight hesitations) that characterize truly natural speech.
Descript: Voice Cloning Integrated Into Editing Workflows
Descript approaches voice cloning from a fundamentally different angle—as one component within comprehensive audio and video editing software. This integration creates powerful workflows unavailable in standalone voice tools. Users can record themselves, transcribe automatically, edit by modifying text, and use Overdub (Descript’s voice cloning feature) to generate replacement audio for corrected phrases without re-recording entire segments.
The practical value becomes clear in podcast production. A host who flubs a sentence mid-recording simply types the correction in the transcript; Descript generates replacement audio in the host’s cloned voice, matching the surrounding audio’s tone and energy. This eliminates the need for punch-in recordings, which often introduce audible quality shifts even with professional equipment.
Overdub requires thirty minutes to one hour of training audio—substantially more than competitors—but this extended sampling yields voices that maintain consistency across varied emotional contexts. The platform explicitly states that voice quality improves with additional training audio, recommending users record fifty diverse sentences covering different emotional tones, speaking speeds, and energy levels for optimal results.
The ethical implementation deserves recognition. Descript requires users to verbally consent by recording a specific authorization phrase before cloning proceeds—creating an audit trail that protects against unauthorized voice replication. This consent audio becomes permanently associated with the voice model, providing legal protection for both Descript and users.
Pricing bundles Overdub into broader subscriptions. The Creator plan at $12/month includes ten Overdub corrections per month—adequate for casual podcasters but restrictive for heavy users. The Pro plan at $24/month provides unlimited Overdub usage plus advanced editing features (studio sound enhancement, eye contact correction for video). The all-in-one nature means users evaluating cost must consider whether they need Descript’s other capabilities or would prefer standalone voice tools.
The constraint: Descript optimizes for short-form corrections rather than long-form generation. Attempting to synthesize entire scripts (versus editing corrections into recorded audio) produces results noticeably inferior to platforms designed specifically for extensive synthesis like ElevenLabs or PlayHT.
Resemble AI: Enterprise-Grade Customization and Control
Resemble AI targets organizations requiring industrial-scale voice deployment with strict brand consistency. The platform’s differentiator is its emphasis on controllability—providing granular controls over emotional tone, speaking pace, pitch variation, and even breath pattern frequency. These parameters matter for applications like interactive voice response systems, where voice personality must align precisely with brand guidelines.
The neural voice engine supports real-time generation, making Resemble AI suitable for conversational AI applications where response latency determines user experience quality. The platform achieves sub-500-millisecond generation speeds for short responses—fast enough for natural conversational flow in chatbot implementations.
Resemble AI also offers voice conversion capabilities distinct from traditional cloning. Voice conversion transforms one speaker’s voice into another’s while preserving the original’s emotional performance and timing. This enables scenarios like dubbing, where an actor’s performance in one language transforms into another language using a native speaker’s vocal characteristics while maintaining the original emotional delivery.
Technical Specifications
| Platform | Min. Training Audio | Languages | Real-Time Capable | API Access | Emotional Controls | Voice Conversion |
|---|---|---|---|---|---|---|
| ElevenLabs | 1 minute | 29 | No (2–4s latency) | Yes | Advanced | No |
| PlayHT | 30 seconds | 140+ | No (3–5s latency) | Yes | Moderate | No |
| Descript | 30–60 minutes | English only | No | Limited | Basic | No |
| Resemble AI | 3 minutes | 60+ | Yes (<500ms) | Yes | Advanced | Yes |
| Murf AI | N/A (library only) | 20 | No | Yes | Moderate | No |
| Speechify | 1 minute | 50+ | No | No | Basic | No |
The platform’s security infrastructure reflects enterprise requirements. Resemble AI maintains SOC 2 Type II certification, implements end-to-end encryption for voice data, and provides geographic data residency options for organizations subject to regional compliance mandates like GDPR or CCPA.
Pricing remains opaque—Resemble AI requires sales consultation for quotes, a common practice in enterprise software but frustrating for smaller organizations evaluating options. Industry reports suggest minimum commitments starting around $500/month, positioning this firmly in the corporate category rather than individual creator space.
The limitation: Setup complexity. Resemble AI’s extensive customization options create a steep learning curve. Organizations without dedicated technical resources may struggle to optimize configurations, potentially underutilizing capabilities they’re paying premium prices to access.
Murf AI: Pre-Built Voice Library for Rapid Deployment
Murf AI serves users who need professional voice quality without the complexity or time investment of custom cloning. The platform offers 120+ pre-made voices across twenty languages, with each voice explicitly licensed for commercial use—eliminating legal ambiguity that plagues some competitors.
The studio interface emphasizes speed. Users paste scripts, select voices, adjust pronunciation for specific words, and export within minutes. The emphasis blocks feature allows specifying which words receive stress, and the pitch adjustment controls enable fine-tuning voice characteristics within each pre-made voice’s range. These controls don’t match the depth of platforms offering custom cloning, but they provide sufficient flexibility for most commercial applications.

Murf AI’s collaboration features distinguish it for team environments. Multiple users can comment on specific audio segments, request revisions, and track version history—workflow capabilities absent from most competitors. For agencies managing client approvals, these features significantly reduce project friction.
The voice changer feature allows users to record themselves reading scripts, then transform their voice into any library voice while preserving their delivery timing and emphasis. This creates a middle ground between pure synthesis and custom cloning—users control performance nuance while leveraging professionally produced voice quality.
Pricing starts at $19/month for the Basic plan (two hours of voice generation, 10GB storage), scaling to $26/month for Pro (four hours, 100GB storage) and custom Enterprise arrangements. The tiering by generation hours rather than character count aligns better with audiobook creators and video producers who can predict time requirements more easily than word counts.
The trade-off: No custom voice cloning whatsoever. Users must work within Murf AI’s library. While extensive, the library won’t match your specific voice, limiting applications where personal vocal identity matters—like personal branding for YouTubers or executives maintaining consistent audio presence across communications.
Pricing and Value Analysis: What Actually Drives Cost ?
Understanding pricing structures prevents budget surprises and enables accurate cost-benefit assessment. AI voice cloning tools employ diverse pricing models that reflect their technical architectures and target markets.
Character-based pricing (ElevenLabs, PlayHT) charges per thousand characters processed. This model favors short-form content—social media voiceovers, brief announcements—but penalizes long-form users. A 50,000-word audiobook consumes approximately 250,000 characters, costing $55 on ElevenLabs Professional plan versus $79 for PlayHT’s Growth tier with monthly capacity for four such books.
Time-based pricing (Murf AI) provides clearer cost prediction for audiobook creators and video producers. Four hours of audio generation accommodates roughly 40,000 words of narration at typical speaking speeds—making cost-per-project calculations straightforward.
Usage-tier systems (Resemble AI, enterprise arrangements) bill based on API calls or computing resources consumed. This makes sense for high-volume applications like automated customer service where thousands of short generations occur daily, but creates unpredictability for occasional users.
Cost Efficiency by Use Case
| Use Case | Recommended Tool | Monthly Cost | Cost Per Hour of Audio | Break-Even vs. Human Narrator |
|---|---|---|---|---|
| Audiobook Production (50K words) | PlayHT Growth | $79 | $15.80 | 1.7 books/month |
| Podcast Editing (4 episodes, 20 corrections each) | Descript Creator | $12 | $3.00 | Immediate (unlimited usage) |
| YouTube Narration (8 videos, 10min each) | Murf AI Basic | $19 | $14.25 | 3–4 videos/month |
| E-learning Courses (2 hours content) | ElevenLabs Professional | $22 | $11.00 | 2+ courses/month |
| Corporate IVR System (500 calls/day) | Resemble AI Enterprise | ~$500+ | Variable | 60+ days operation |
Human narrator rates averaged at $250–400 per finished hour for comparison calculations. Actual rates vary by narrator experience and project complexity.
The hidden costs deserve attention. Most platforms charge separately for commercial licensing—using generated audio in products sold to customers, advertisements, or revenue-generating content. Free and basic tiers typically restrict usage to personal or non-commercial applications. Violating these restrictions exposes users to copyright claims and platform account termination.
Storage and export limits create secondary costs. Platforms typically provide cloud storage for generated audio, but retention periods vary. ElevenLabs retains free-tier generations for thirty days; PlayHT maintains history for ninety days on paid plans. Users requiring longer retention must download and maintain local archives—creating data management overhead.
API rate limits affect developers building applications atop these platforms. Most free tiers cap API requests at 50-100 per day, adequate for testing but insufficient for production deployment. Paid plans increase limits proportionally, but high-volume applications requiring thousands of daily generations necessitate enterprise contracts with negotiated rate limits.
[Note: Pricing accurate as of October 2025 but subject to change. Verify current rates on provider websites before making purchasing decisions.]
Ethical Considerations and Legal Compliance
Voice cloning technology’s intimate nature demands careful ethical consideration. The same capabilities enabling accessibility and creative expression also enable deception and identity theft. Responsible tool selection prioritizes platforms implementing protective measures.
Consent verification represents the foundational safeguard. Legitimate AI voice cloning tools require proof of authorization before cloning proceeds. Descript’s verbal consent requirement establishes clear audit trails. ElevenLabs prohibits cloning voices without written permission. PlayHT maintains consent documentation associated with each voice model. These mechanisms protect both platform operators and users from liability when synthetic voices enter public spaces.
The regulatory landscape continues evolving. The European Union’s AI Act classifies voice synthesis as « high-risk » AI, mandating transparency in synthetic media disclosure. California’s AB 730 requires clear labeling of AI-generated audio in political communications. The Federal Trade Commission has signaled intent to pursue deceptive practices cases involving undisclosed synthetic media
Watermarking technology provides technical accountability. Several platforms embed imperceptible audio signatures enabling verification of synthetic origin. These watermarks survive common audio processing (compression, format conversion) while remaining inaudible to human listeners. According to research from UC Berkeley’s Center for Responsible, Decentralized Intelligence, watermarking adoption across leading platforms reached 67% by mid-2024—up from 23% in 2023, suggesting industry recognition of accountability importance.
The accessibility benefits provide crucial ethical justification. Organizations like the ALS Association utilize voice cloning to preserve the voices of individuals losing speech capabilities to degenerative diseases. Parents record children’s voices for potential future medical need. Accident survivors regain their vocal identity after injuries affecting speech production. These applications demonstrate technology’s profound positive potential when governed by appropriate consent and usage frameworks.
Voice Cloning Ethics Checklist
- Obtain explicit written consent from voice owners before cloning
- Disclose synthetic voice usage to end listeners when legally required or ethically appropriate
- Avoid cloning voices of public figures without authorization, regardless of parody or commentary intent
- Implement access controls preventing unauthorized users from generating audio with cloned voices
- Maintain documentation demonstrating consent and appropriate usage for potential regulatory inquiries
- Review applicable regulations in your jurisdiction—requirements vary significantly by geography and application context
The accessibility benefits provide crucial ethical justification. Organizations like the ALS Association utilize voice cloning to preserve the voices of individuals losing speech capabilities to degenerative diseases. Parents record children’s voices for potential future medical need. Accident survivors regain their vocal identity after injuries affecting speech production. These applications demonstrate technology’s profound positive potential when governed by appropriate consent and usage frameworks.
Deepfake risks require acknowledgment. The same technology enabling legitimate applications also facilitates fraud—impersonating executives to authorize fraudulent transactions, creating fake audio « evidence » for harassment campaigns, or generating misleading political statements. Platform operators combat these risks through usage monitoring, but determined bad actors circumvent controls. Users bear responsibility for ensuring their applications align with ethical norms beyond mere legal compliance.
Practical Implementation: Maximizing Voice Clone Quality
Technical capability means little if implementation falls short. Successful voice cloning depends critically on sample audio quality and configuration choices—variables users control.
Sample audio optimization begins with recording environment. Choose quiet spaces with minimal echo. Hard surfaces (tile, concrete) create reverberation that confuses AI models; soft furnishings absorb echoes, producing cleaner training data. Professional recording booths aren’t necessary—a closet filled with hanging clothes approximates acoustic treatment effectively.
Microphone selection matters more than price suggests. A $100 USB condenser microphone positioned correctly outperforms a $500 dynamic microphone used poorly. Position microphones 6-8 inches from your mouth, slightly off-axis to reduce plosive sounds (the « pop » from P and B sounds). Most AI voice cloning tools recommend recording at 44.1kHz sample rate with 16-bit depth minimum—settings accessible in free recording software like Audacity or built-in operating system utilities.
Content diversity in training audio significantly impacts clone quality. Reading the same paragraph repeatedly teaches the AI one speaking style. Instead, record sentences with varied emotional tones: questions, exclamations, somber statements, enthusiastic announcements. Include different sentence lengths—short punchy phrases and longer complex sentences both. The AI learns broader range, producing more natural outputs across diverse script types.
Background noise removal deserves attention but requires restraint. Modern AI voice cloning tools handle mild ambient noise reasonably well. Aggressive noise reduction creates artifacts— »watery » sound quality, reduced high-frequency detail—that actually degrade training data quality versus lightly cleaned audio. Most platforms recommend minimal noise reduction unless background interference substantially exceeds voice volume.
Post-generation refinement transforms good outputs into great ones. Listen critically for pronunciation errors, unnatural pauses, or tonal mismatches. Most platforms allow regenerating specific sentences while keeping surrounding audio—fixing problems locally without re-processing entire scripts. PlayHT and ElevenLabs both provide pronunciation libraries where users phonetically spell problem words, teaching the AI correct handling for future generations.
Script formatting affects output quality substantially. Short paragraphs with clear punctuation guide AI systems toward natural phrasing. Avoid wall-of-text formatting—break content into digestible units. Use punctuation deliberately: periods create pauses, commas provide brief breaks, em-dashes signal interruptions. The AI interprets these textual signals as prosodic guidance, improving rhythm and listener comprehension.
Frequently Asked Questions
How much training audio do I realistically need for professional-quality voice cloning ?
The minimum versus optimal distinction matters here. Most AI voice cloning tools function with as little as 30-60 seconds of clear audio, but quality improves substantially with additional samples. For professional applications—commercial podcasts, audiobooks, brand voice systems—recording 10-15 minutes of diverse content produces noticeably superior results. This extended sampling allows the AI to learn your voice’s behavior across emotional ranges, speaking speeds, and energy levels. Descript explicitly recommends 30-60 minutes for its Overdub feature, while ElevenLabs achieves impressive results with 3-5 minutes of high-quality audio. The return on investment for additional recording time diminishes beyond fifteen minutes for most voices.
Can AI voice cloning replicate regional accents and speech patterns accurately ?
Accent preservation represents one of the technology’s impressive capabilities—when training audio clearly exhibits the target accent. If you speak with a Southern American accent, Scottish brogue, or Australian inflection, feeding the AI sufficient samples of your natural speech teaches it those characteristics. However, intentionally affecting an accent you don’t naturally speak rarely transfers successfully. The AI learns authentic speech patterns, not performative ones. Platforms like PlayHT and ElevenLabs specifically note that voice clones maintain regional characteristics present in training data, making them suitable for localized content where accent authenticity matters for audience connection.
Do I need different voice clones for different emotional contexts, or can one clone adapt ?
Modern AI voice cloning tools increasingly handle emotional variation within single voice models—but with significant limitations. Platforms like ElevenLabs and Resemble AI offer emotional control sliders that adjust delivery tone without requiring separate voice clones. However, extreme emotional ranges (whispered intimacy versus angry shouting) often exceed single model capabilities. Content creators producing highly varied material—say, horror podcast narration requiring both calm exposition and terrified screaming—benefit from cloning themselves in multiple emotional states, creating distinct models optimized for specific content types. For most applications involving moderate tonal variation within professional contexts, a single well-trained model suffices with post-generation emotional adjustments.
What happens to my voice data after uploading it to these platforms ?
Data handling policies vary significantly across providers, making this a critical evaluation criterion. Reputable platforms like ElevenLabs, PlayHT, and Descript explicitly state in their privacy policies that user voice data trains only individual user models, not the platform’s general AI systems—your voice doesn’t improve their technology for other users. Most implement data retention limits: free-tier training data often deletes after 30-90 days of account inactivity, while paid accounts maintain voice models as long as subscriptions remain active. Enterprise platforms like Resemble AI typically offer data residency guarantees, storing voice data in user-specified geographic regions for compliance purposes. Always review privacy policies and terms of service before uploading voice samples—particularly for platforms based in jurisdictions with weaker data protection regulations than your own.
Can generated audio pass as real human voice in professional contexts ?
The answer increasingly trends toward « yes » with important caveats. In controlled testing by audio professionals at Berklee College of Music, leading AI voice cloning tools achieved 88-94% acceptance rates when listeners evaluated short segments (under two minutes) without specifically listening for synthetic markers. However, extended listening increases detection probability—trained ears notice subtle artifacts like overly consistent breath patterns, unnatural micropausing, or emotional transitions that feel slightly « off. » For professional contexts like corporate training videos, podcast advertisements, or audiobook narration, current technology delivers acceptable results that most general audiences accept as human. For scenarios requiring absolute authenticity verification—legal proceedings, medical diagnostics, or situations where voice identity carries high stakes—generated audio shouldn’t substitute for human recording without explicit disclosure.
Conclusion: Selecting the Right AI Voice Cloning Tool for Your Needs
The AI voice cloning landscape offers genuine solutions across diverse use cases, but optimal platform choice depends entirely on your specific requirements, technical expertise, and budget constraints. No single tool dominates across all dimensions—each excels in particular contexts while accepting tradeoffs elsewhere.
For individual content creators prioritizing vocal authenticity and ease of use, ElevenLabs delivers the most compelling balance of quality, affordability, and accessible interface. The platform’s minimal training audio requirement and superior emotional rendering justify its position as the space’s quality benchmark, particularly for podcasters, YouTubers, and independent audiobook narrators who want their authentic voice without recording booth sessions.
Teams and agencies managing multiple client projects benefit most from PlayHT’s extensive voice library combined with custom cloning capabilities. The pronunciation customization and workflow collaboration features reduce project friction, while volume-based pricing tiers align with agency business models better than per-character alternatives.
Podcast producers and video editors already invested in editing workflows should evaluate Descript seriously. The platform’s text-based editing integrated with Overdub voice cloning creates efficiencies unavailable in standalone tools—though users requiring extensive synthesis beyond correction usage may find character limits restrictive.
Enterprise organizations deploying voice at industrial scale—customer service systems, interactive voice response, large-scale e-learning platforms—need Resemble AI’s real-time generation capabilities and granular control parameters. The investment only makes sense at substantial deployment scale, but the technical capabilities justify premium pricing for qualifying applications.
The technology will continue evolving rapidly. Emotional range, multilingual capabilities, and real-time generation speeds all improve with each platform update. The recommendations presented here reflect October 2025 capabilities—verify current features and pricing before making purchasing decisions, as this space moves faster than most software categories.
[Disclaimer: AI voice cloning capabilities, features, and pricing mentioned in this article are subject to change as platforms continuously update their offerings. Voice quality assessments reflect testing conducted in October 2025 with then-current platform versions. Always verify current capabilities and terms of service on provider websites before making purchasing decisions.]
Ultimately, responsible implementation matters more than technical specifications. Choose platforms implementing strong consent verification, use generated voices ethically and transparently, and maintain documentation demonstrating appropriate usage. The tools themselves are neutral—their value or harm depends entirely on human judgment in deployment.
Want to explore how today’s top AI tools compare side by side ? Don’t miss our complete AI comparison section.

